There are a million tools out there for monitoring services and measuring application performance, and I’m sure many of them are awesome.
When I went looking for a good service and infrastructure monitoring solution for our community newspaper’s one-person IT department (me), I came back to an open source tool that I’d probably first started using over 20 years ago: Nagios.
It works great for us and only costs $4/month to self-host. I thought I’d share about how we’re using it in case others might find it helpful.
My needs were pretty straightforward.
I wanted to monitor 10 or so servers and network devices and various services hosted on them, the health of 20 or so web applications, and the status pages of about 20 external services/platforms we depend on.
When something gets slow or stops responding, I wanted to know about it in a reliable way.
We’d used Nagios extensively at the website development and hosting business I ran a long time ago, and it was great for this kind of thing. Highly configurable and flexible, low maintenance, and very reliable.
When looking at options more recently, Nagios didn’t seem to have changed much in all that time, and with its outdated web interface and arcane config file syntax, I convinced myself that someone had surely created a better tool by now. So, I spent a bunch of time researching alternatives, including Zabbix, Prometheus, Grafana, Datadog, New Relic, Pingdom, UptimeRobot, and a bunch of others. And we did start out using UptimeRobot for a brief while.
But when I looked at the amount of time I was going to spend learning and managing the complexity of those stacks, or the amount of money we would spend on SaaS tools along with some of the constraints and “per seat” or “per monitor” limits they imposed, the more I was ready to go with a tried and true, purpose-built option that could scale up without additional cost or complexity.
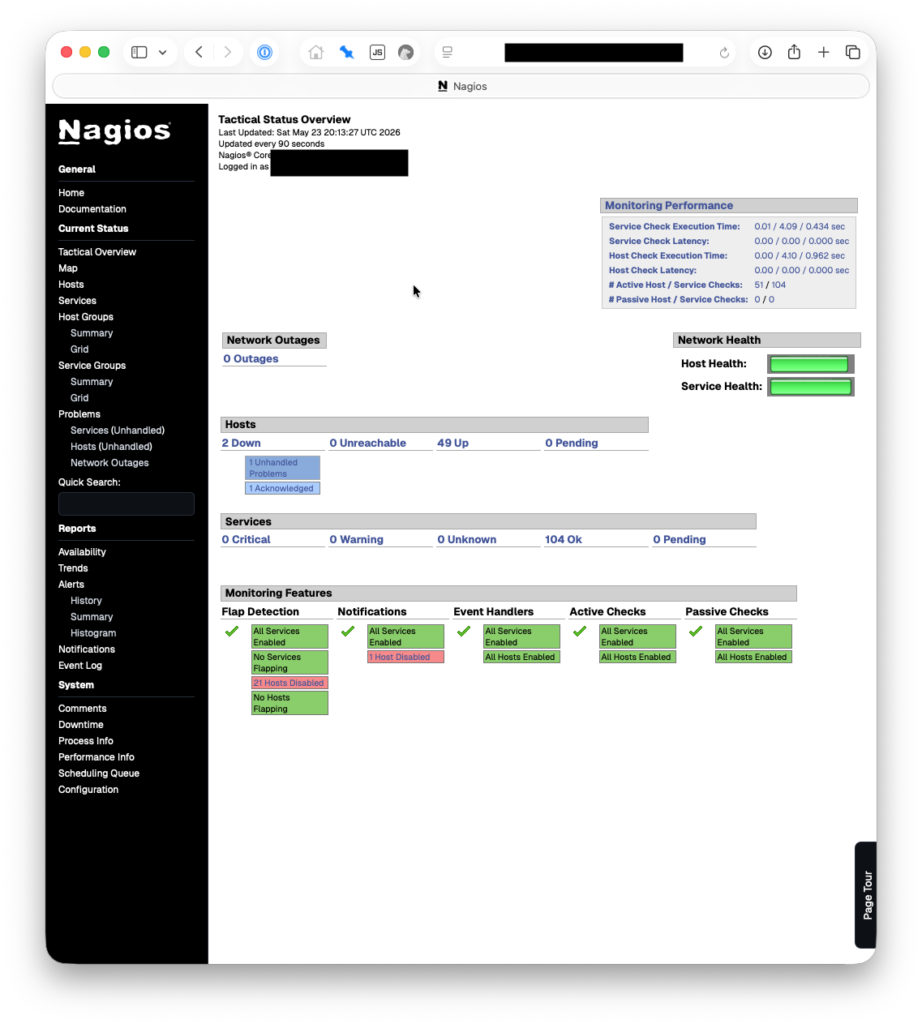
Nagios is not fun to set up initially — see my earlier comment about arcane config syntax. It probably took me the equivalent of a full day to get everything just so. But once I did, it’s been humming along great, and brings significant peace of mind.
We’re currently monitoring 54 hosts and 104 services. This is all on a $4/month droplet at Digital Ocean, 1 vCPU, 512 MB RAM, 10 GB Disk. We pay another $0.80/month for weekly droplet snapshots. We set our monitoring droplet up in a different physical region from the rest of our servers/droplets, on the other side of the continent.
My SaaS app WP Lookout uses Amazon Web Services for hosting. I’ve had plenty of monitoring set up using both internal and external tools notifications, and these mostly output to a combination of a dedicated Slack channel and/or a Pushover notification that goes to my mobile device.
The one thing I didn’t have in place until recently was monitoring for the health of the specific group of AWS services the app depends on. With AWS offering many services spread across many parts of the world (as illustrated in the Very Long Service Health Dashboard), I wasn’t about to start monitoring all of the AWS infrastructure just to see if my particular app was affected.
They do offer a “Personal Health Dashboard” that’s supposedly more tailored to incidents affecting my AWS account, but I find it unintuitive and confusing to use, especially when it comes to setting up notifications to external services like Slack. In my online searching I found various services and tools that supposedly integrated the PHD into more standard monitoring and alerting options, but they were also either too complicated or seemed to require additional levels of paid AWS support plans that I didn’t want to take on.
So I decided to keep things simple and use the tried and true technology for polling information about external resources: RSS!
Our household uses Apple’s Time Machine backup system as one of our backup methods. Various Macs are set to run their backups at night (we use TimeMachineEditor to schedule backups so they don’t take up local bandwidth or computing resources during the day) and everything goes to a Synology NAS (basically following the steps in this great guide from 9to5Mac).
But, Time Machine doesn’t necessarily complete a successful backup for every machine every night. Maybe the Mac is turned off or traveling away from home. Maybe the backup was interrupted for some reason. Maybe the backup destination isn’t on or working correctly. Most of these conditions can self-correct within a day or two.
But, I wanted to have a way to be notified if any given Mac had not successfully completed a backup after a few days so that I could take a look. If, say, three days go by without a successful backup, I start to get nervous. I also didn’t want to rely on any given Mac’s human owner/user having to notice this issue and remember to tell me about it.
I decided to handle this by having a local script on each machine send a daily backup status to a centralized database, accomplished through a new endpoint on my custom webhook server. The webhook call stores the status update locally in a database table. Another script runs daily to make sure every machine is current, and sends a warning if anyone is running behind.
Here are the details in case it helps anyone else.
Let’s say your WordPress site has some set of custom functionality that is important to the overall operation of the site, and you want to know right away if it’s not working as expected, even if the site is otherwise “up” and working fine. There could be anywhere from 0 to many things needing attention at any given time, and you don’t want to receive a flood of emails or Slack pings that you have to sort through, you just want a single alert that things are off track, and another notice when they’re back to being in good shape.
I recently handled this case using transients, a custom REST API endpoint, and the service UptimeRobot. The context for me was a set of functions that regularly retrieve information from a variety of third-party sources; most of the time it goes fine, but between network issues, changes in third-party API endpoints or HTML source code and other possible errors, occasionally these functions would break and need updating.
First, I established an error function that was called any time some aspect of my site’s custom functionality encountered a problem that might need my attention.
When called, this function increases the counter of the number of errors interacting with a passed third party data source, storing that counter in a transient. As my custom functions run, any failures will be recorded for up to 24 hours. If there are no additional failures to increase the counter and extend the transient expiration time, then the failure data will go away with the assumption that things are back to normal now. (You may need to adjust these assumptions for your use case.)
Then, I create a REST API endpoint on the site that allows me to monitor that failure data externally.
And then a callback function to determine the content of that API endpoint:
public static function mysite_event_fetch_status() {
$error_count = 0;
foreach ( array( 'facebook', 'eventbrite', 'googlecal' ) as $event_source ) {
$fail_data = get_transient( 'event_fetch_failure_' . $event_source );
if ( false !== $fail_data ) {
$error_count += $fail_data['count'];
}
}
if ( 0 < $error_count ) {
echo sprintf( 'There have been %d recent event fetch errors.', (int) $error_count );
} else {
echo 'OK';
}
}
Now, I have a REST API endpoint available at https://example.com/wp-json/mysite/v1/event_fetch_status that will either return OK if there have been no recent problems, or an error message with a count of recent issues. I could expand that output to include more detail about which third-party services are having issues and what those issues are, but for the purposes of a red versus green monitoring setup, the basics are fine and I can look into the details when I investigate.
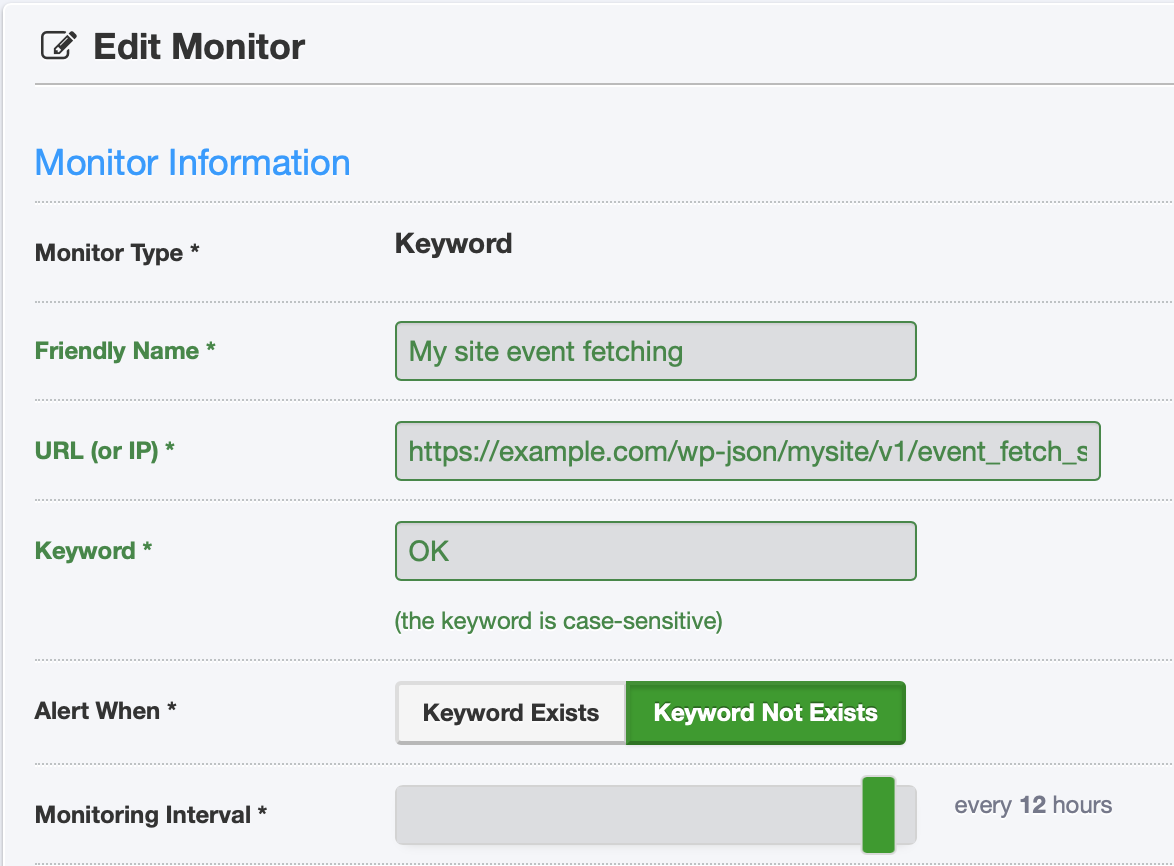
Finally, I set up a monitor in UptimeRobot to check that endpoint on a regular basis and notify me if there’s a problem:
UptimeRobot monitor screenshot
Just for good measure, I also create an admin notice in the WordPress admin area with a little more detail about what is failing:
All put together, I will now receive alerts as configured in UptimeRobot when my custom functions have issues.
You could go the typical route of generating an email or Slack message about each problem, but in my experience this can quickly create a lot of one-off monitoring and alerting configurations in your life, and that can lead to you missing important information or being desensitized to the notices. Instead, I find it’s worth trying to manage all of my time-sensitive notifications across all of my various projects and services in one place where possible, and UptimeRobot or similar services offer a lot of flexibility for that.